Nós sempre precisamos guardar os dados que manipulamos em nossos programas. Algumas vezes basta utilizar um arquivo, como por exemplo para guardar as configurações de um programa ou o escore de um jogo, mas para a maioria das aplicações empresariais, guardar dados significa: acessar um banco de dados, inserir, editar, apagar e manipular informações.
Uma forma de realizar esta tarefa é acessando diretamente o banco de dados, controlar cada atividade utilizando comandos SQL. Já vimos em
um post anterior como criar uma conexão com um banco de dados.
Outra forma é realizar a persistência usando a
biblioteca Hibernate. Este pacote realiza um mapeamento tipo objeto-relacional fornecendo um framework para mapear os objetos na linguagem Java para um banco de dados relacional tradicional (como SQL Server, MySQL, Oracle, Apache Derby ou outros).
Hibernate irá mapear classes Java para tabelas do banco de dados e mapeara os tipos de dados Java em tipos SQL, além de fornecer métodos de pesquisa de dados (realização de Query) e outros métodos de acesso a dados, gerando as chamadas SQL para nós e também manipulando os resultadores retornados pelo banco de dados utilizando estruturas de classes. Com isto as aplicações são portáveis para diferentes bancos de dados, bastando trabalhar as configurações de persistência, pois as operações são sempre iguais. O impacto em performance é pequeno em relação ao ganhos obtidos em facilidade de programação e portabilidade.
O mapeamento das classes Java em tabelas é feito por meio de configurações em arquivos XML ou utilizando Annotations. Eu particularmente prefiro Annottations, pois a indicação no código é bastante esclarecedora e nos economiza a necessidade de ter que criar arquivos XML para o esquema de persistência.
Hibernate ainda permite a criação de relacionamentos 1-para-muitos e muitos-para-muitos. Também permite criar relacionamentos reflexivos onde um objeto que possuir uma relação um-para-muitos com outras instâncias de sua classe. Temos suporte para herança, polimorfismo, composição e Java Collection. Com Hibernate temos condições de suporte a geraçao automática da chave primária.
O Hibernate é tão flexível que permite que criemos mapeamentos para tipos customizados, do tipo:
- sobrepor um tipo SQL quando mapeamos uma coluna a uma propriedade da classe;
- mapear um tipo Enum Java para colunas com se elas fossem propriedades regulares;
- mapear uma propriedade para múltiplas colunas em uma tabela.
Hibernate provê três mecanismos de pesquisa:
- Hibernate Query Language (HQL)
- Hibernate Criteria Query API e
- suporte para pesquisas em formato SQL nativo do banco de dados.
A arquitetura do Hibernate pode ser representada pelo diagrama abaixo:
Existem 3 principais componentes no Hibernate:
Hibernate Connection fornece uma forma fácil de administrar as conexões com o banco de dados. Esta normalmente é a parte mais dispendiosa na interação com o BD utilizando muitos recursos para abertura e fechamento de conexões.
O Transaction management fornece a capacidade do usuário executar mais de uma chamada ao banco de dados ao mesmo tempo.
- Object relational mapping
O mapeamento Objeto-Relacional é uma técnica que mapeia (traduz) da representação dos dados no modelo de objeto (os objetos e suas propriedades) em um modelo de dados relacionais (as tabelas e colunas). Este mapeamento é utilizado para selecionar, inserir, atualizar e apagar registros em uma tabela.
Quando enviamos um objeto para o método Session.save() do Hibernate, este lê o estado das variáveis deste objeto e executa a query necessária.
Chega de falação...leia no próximo post o nosso primeiro exemplo de Hibernate.
Nos próximos posts, vamos ver como criar o arquivo de configuração de persistência, vamos criar uma classe a ser persistida utilizando o mapeamento por XML e usando Annottations.





















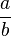 , designa o inteiro
, designa o inteiro



{kind=link}